昨天华为正式提出了“韬(τ)定律”,在全行业引发了激烈讨论。
关于韬(τ)定律的基本情况,我们已经在昨天的文章中进行了分析(不清楚的可以点进主页查看)。关于韬(τ)定律和逻辑折叠技术本身,目前还缺乏一些必要的技术细节。
今天我们就一些公开的资料,来综合分析一下韬(τ)定律会给接下来华为麒麟处理器带来哪些新的改变。
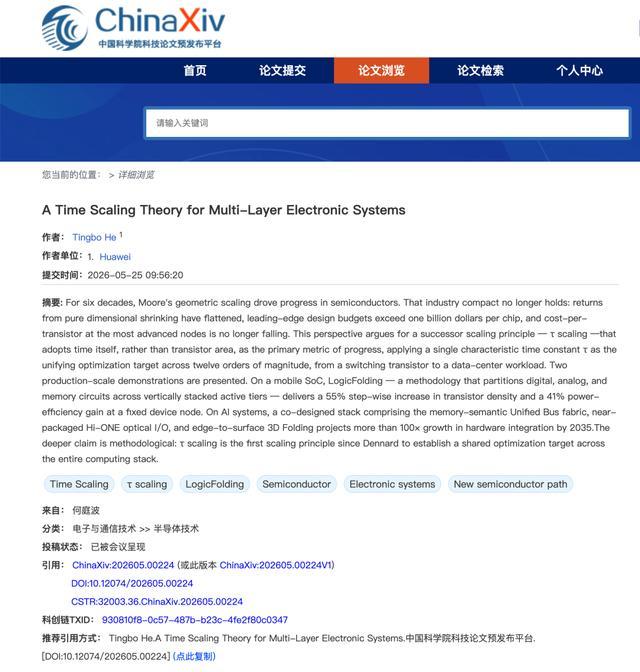
关于韬(τ)定律,除了目前公布的一些官方信息之外,最权威和核心的资料,是华为半导体团队负责人何庭波在中国科学院科技论文预发布平台发表的一篇名为《A Time Scaling Theory for Multi-Layer Electronic Systems》(多层电子系统的时间缩放理论)的文献。
华为团队的韬(τ)定律,最核心的观点就是,将半导体的核心考量指标从空间面积变成时间。
背后的逻辑很简单:普通用户买手机、用 AI,并不会在乎里面的晶体管到底是几纳米(空间)。用户在乎的是:打开软件快不快?大模型回复省不省时?这本质上追求的是时间概念。
此前半导体行业拼命把晶体管做小,本质上也是为了让电信号少跑路,从而节省时间。
既然如此,为什么不把缩短时间作为追求半导体性能的终极目标呢?
这就是韬(τ)定律的核心逻辑。在全新的韬(τ)定律下,评价一款芯片性能的强弱将不再单看制程,而是要看整个计算系统内,完成一次任务需要耗费的时间(即时间常数τ)。 在此基础上,华为半导体团队拿出了最核心的一项技术,就是“逻辑折叠(Logic Folding)”。
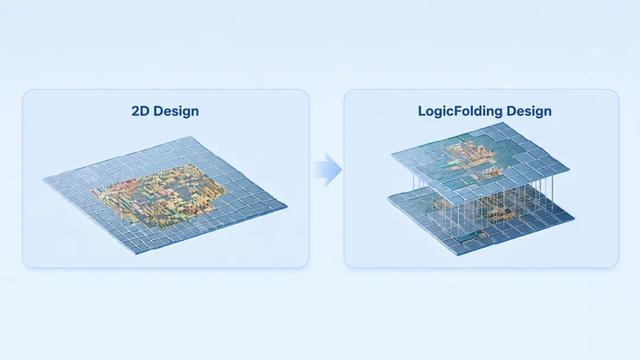
这项技术的核心原理,昨天我们已经在文章中介绍过。简单说,华为把原本平铺在二维平面上的数字逻辑电路、模拟电路和内存,通过极为精密的技术垂直叠在一起。以前两个晶体管要横跨大半个芯片才能通信,现在就像“楼上楼下”,坐个电梯就到了。
在文献中,华为详细说明了逻辑折叠技术带来的性能和能效红利。
通过逻辑折叠技术,华为实现了在固定工业制程节点下空间利用率的突破。以采用了该项技术的 Kirin 2026(代号)为例,它的晶体管密度从上一代的 155 MTr/mm² 阶跃式提升至 238 MTr/mm²,实现了 55% 的晶体管密度提升。
换句话说,在工艺制程不变的情况下,采用逻辑折叠技术的麒麟芯片,在同样的物理尺寸下实现了 55% 的晶体管密度增长。而如果是要依靠传统的提升工艺制程来实现同等晶体管密度的提升,行业通常需要耗费 3 年的研发周期。 新技术带来了算力和能效的双重提升。

通过缩短信号传输距离,减少了电阻电容浪费。华为 Kirin 2026 芯片实现了 13% 的最大时钟频率提升。华为在文献中提到,Kirin 2026 芯片今年最高的核心运行频率将提升至 3.1 GHz。相比之下,目前华为手机处理器最强的麒麟9030 Pro最高的核心运行频率为2.75GHz。
与此同时,其 SoC 性能核心的功耗效率也提升了 41%。此外,通过后硅片时钟偏斜调整方案,华为又独立为 SoC 贡献了超过 5% 的系统性能增益。
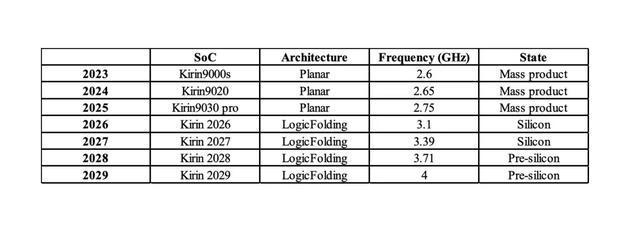
文献还披露了这一技术路线带来的 Kirin CPU 性能核心最高频率的演进规划趋势:
2026 年(Kirin 2026):首次导入逻辑折叠架构,频率达到 3.1 GHz(目前处于 Silicon 硅片阶段);
2027 年(Kirin 2027):折叠架构升级,频率推升至 3.39 GHz(处于 Silicon 硅片阶段);
2028 年(Kirin 2028):频率推升至 3.71 GHz(处于 Pre-silicon 预硅设计阶段);
2029 年(Kirin 2029):频率将正式触及 4.0 GHz 门槛。
该文献还明确指出,麒麟 2026 采用的逻辑折叠方案在工艺上还是相对保守的。随着未来低温键合等工艺的演进,技术将转向完全体的三层、四层乃至更多层的全尺寸逻辑折叠。
在这一技术和理论的指导下,未来 3~5 年内麒麟处理器在用户典型使用场景下,整体效率预计将实现一倍以上的增长!这将极大提升未来华为手机的性能和功耗表现。
还有一个被很多人忽视的细节就是,除了逻辑折叠技术之外,文献中还有一项非常重要的技术,即:统一总线(Unified Bus)。该技术主要针对 AI 大模型算力集群和数据中心(大规模多芯片协同系统)。

在传统架构中,数据要在不同芯片之间传输,需要经过多层物理和软件协议的转换。每一层转换都会带来额外的序列化、DMA 缓冲区开销和深层握手,带来额外的时延和功耗。
Unified Bus (UB) 直接用一种统一协议,取代了上面整套复杂的传统堆栈。这个协议不仅能在同一个机箱内跑,还能直接跨机箱在整个数据中心网络里跑。
通过这一全栈式的重构,华为披露了 Unified Bus 带来的性能提升:
端到端的远程访问延迟从传统 TCP/IP 类网络软件栈的几十微秒(Tens of Microseconds),直接骤降到了大约 100 纳秒(~100 ns)。在 AI 集群最核心的通信轴上,实现了高达 ~500 倍的系统时间常数(τ)压缩。
另外通过该项技术,分布式机柜中的千百颗芯片通过 UB 紧密编织在一起,数据互连无损且无感知,使整个集群无限逼近一台统一的、单体的算力中心。
总的来说,华为半导体团队提出的“韬(τ)定律”是国产半导体领域一次非常重大的理论和技术突破。华为不仅拿出了全新的理论研究体系,还基于这一理论拿出来实实在在的应用技术。尤其是在当前摩尔定律红利放缓,国产半导体存在“卡脖子”的背景下,华为这套理论体系和技术路线浙江配资门户,不仅能够极大提升国产芯片的整体性能,还为后摩尔定律时代半导体行业的多元化突围,提供了一种全新的路径。这是非常了不起的成就!
益筹配资提示:文章来自网络,不代表本站观点。



热点资讯